Insert speed and Postgres indexes
17 October 2019
Adding too many indexes has a cost, we are going to run through some example data and what size of an impact it looks like
A common rules of thumb is to add indexes to any field that needs to be queried, in most cases this will work out fine but the read performance has a cost. In our example we a ‘widgets’ table and we will add a few indexes and check the performance.
This is our table setup:
\timing
CREATE TABLE widgets (
field1 text,
field2 text,
field3 text,
field4 text,
field5 text
);Collecting data on insert performance:
SELECT FROM generate_series(1, 10000);
-- Time: 3.774 ms
INSERT INTO widgets SELECT FROM generate_series(1, 10000); truncate table widgets;
-- Time: 18.334 ms
CREATE INDEX widgets_name1 on widgets (field1); truncate table widgets;
-- Time: 32.894 ms
CREATE INDEX widgets_name2 on widgets (field2); truncate table widgets;
-- Time: 46.093 ms
CREATE INDEX widgets_name3 on widgets (field3); truncate table widgets;
-- Time: 50.078 ms
CREATE INDEX widgets_name4 on widgets (field4); truncate table widgets;
-- Time: 62.191 ms
CREATE INDEX widgets_name5 on widgets (field5); truncate table widgets;
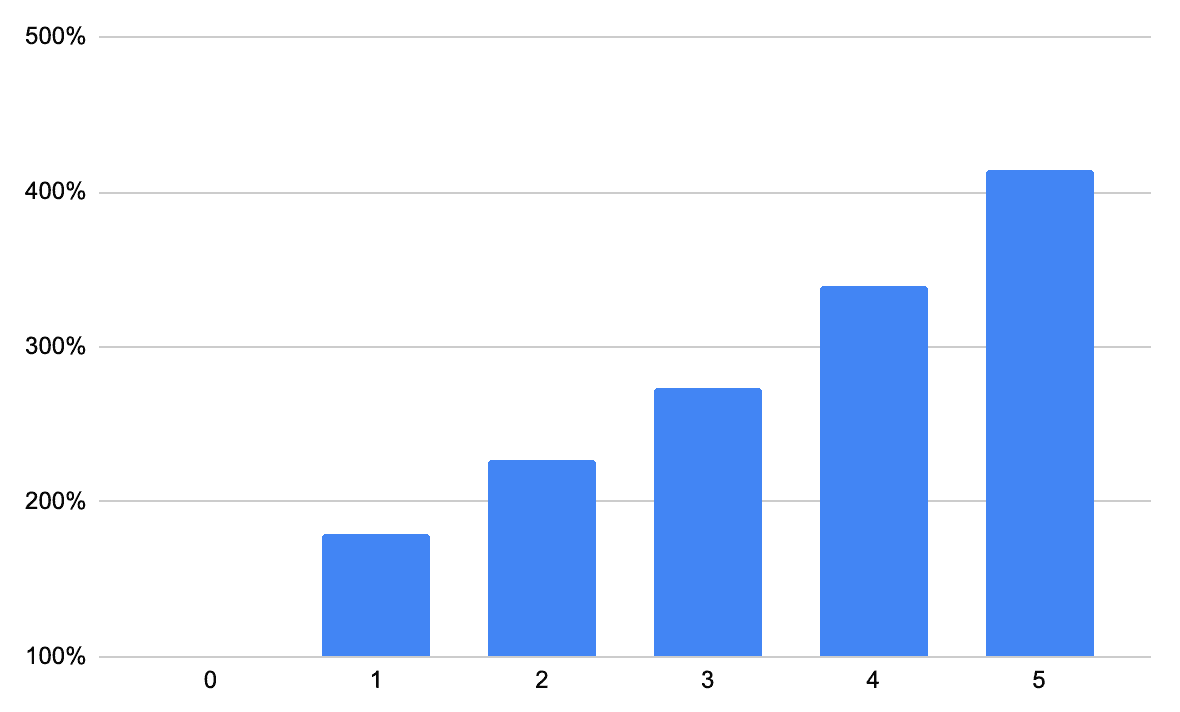
-- Time: 75.838 msFrom this we can see an upward trend with number of indexes slowing down insert time. By using 0 indexes as the baseline we can make a pretty chart for visualization:
For extreme performance, have 0 indexes. This is a little hard to get to because normally we want to select things, at least by a primary key. If we are maximizing for insert speed it will be pretty slow without an index for the read side. An option here is a read replica, and deal with duplicate primary keys downstream on the reader side instead of writer side.
Beyond that each additional index adds an additional thing to update per insert insert. This is dummy data and the times come from my local computer (specs not included), but it is worth knowing that indexes are a good place to look for insert performance.